


Python scripts can be used to download, extract, and upload files to AWS S3. The challenge is to accomplish this without relying on a local or server machine for downloading the zip folder. To address this, AWS EC2 can be utilized to host the python script responsible for the download, extraction, and upload actions to S3. From a variety of options offered by AWS, a server instance with the appropriate configuration is selected for this purpose on EC2.
With python, we will utilize RedditApi to extract data from Reddit, transform that data and finally load into an S3 bucket. Next, we will set up an Airflow instance and deploy the python scripts to schedule the task.
The above will be carried out in the following steps:
Spin up EC2 instance and create S3 bucket for the project.
Install required packages for the pipeline project
Deploy python scripts and schedule workflow on Airflow.
Here is our architecture

Step 1A: Stand up the EC2 Instance.
To get started with AWS EC2 for your pipeline project, log in to your AWS account and go to Services > EC2. Launch an instance and choose the Ubuntu AMI. On the next screen, select an appropriate instance size considering your workload requirements. It's recommended to choose a larger instance like t2.medium for small workloads or even m5a.xlarge for production versions. Make sure to enable the "Auto-assign Public IP" option. Accept the default settings for the remaining screens.

EC2 Instance
When setting up the security group, add a rule to open port 8080 for public access, which is the port used to connect to the Airflow server.

Security group
Finally, we attach an IAM Role to the EC2 to enable it have access to write to the S3 bucket
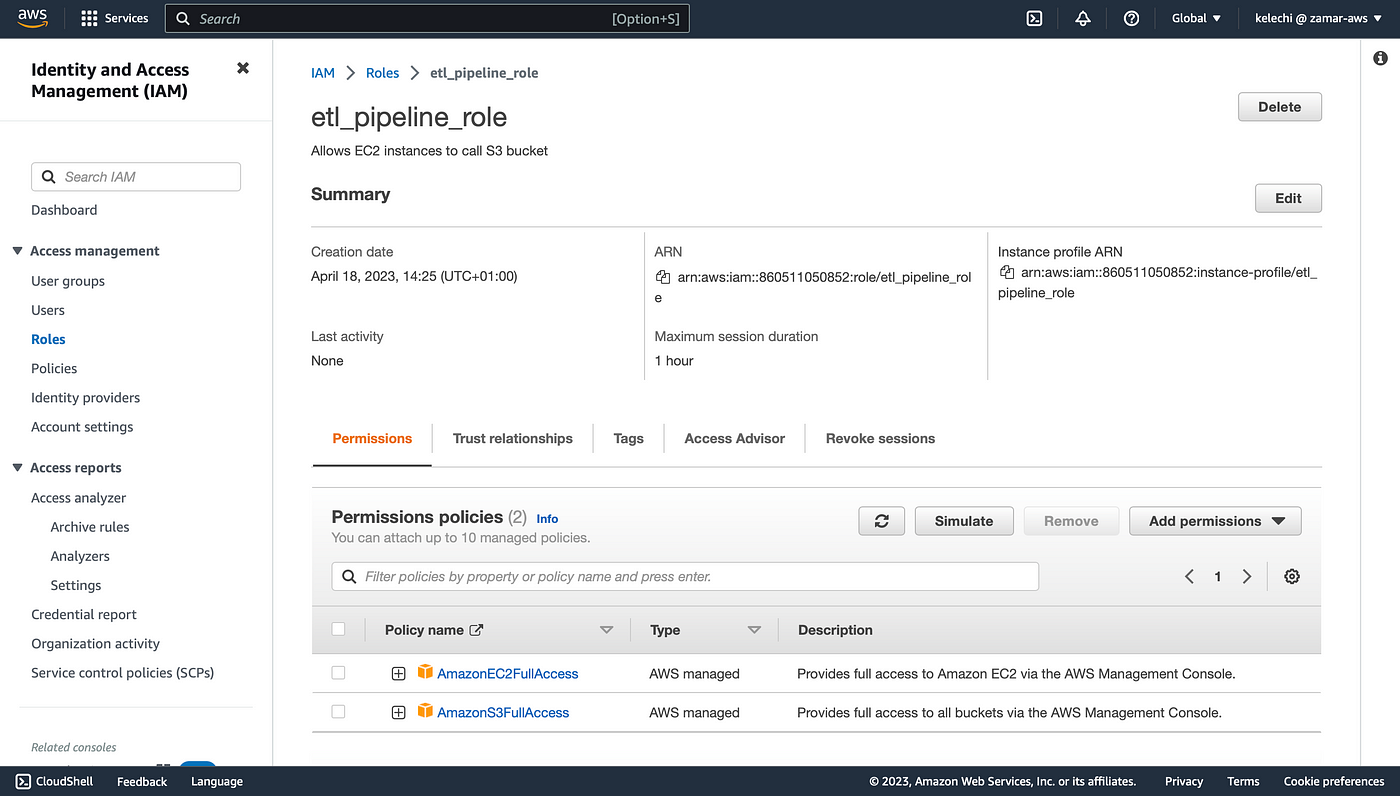
IAM Role
Step 1B: Create S3 bucket where the data will be stored.

S3 bucket
Step 2: Install required packages for the ETL pipeline project
We ssh into the EC2 instance, create a virtual environment and install required packages on the EC2 instance.
i. Install ubuntu software updates.
sudo apt-get update

updating dependencies
ii. Then we create a virtual environment for our project in the ec2 home directory and activate it.
#to install python3.10-venv package
sudo apt install python3.10-venv
#to create a virtual environment
sudo python3 -m venv airflow_reddit/env
#to activate the virtual environment
source ~/airflow_reddit/env/bin/activate

installing python3.10-venv package
iii. Next, we install Apache Airflow, an open-source platform for orchestrating complex data workflows and pipelines.
sudo pip install apache-airflow

Airflow installation
#to confirm airflow installation
airflow
Confirming airflow installantion
iv. Then, we install Pandas which is a python data analysis and manipulation library for efficient data handling.
sudo pip install pandas

Installing Pandas
v. Next we install s3fs, a Python library that provides a file system interface for interacting with Amazon S3, allowing users to read and write data from and to S3 using familiar file system operations.
sudo pip install s3fs

Installing S3fs
Step 3: Deploy Code and shedule our workflow on airflow
This typically involves defining tasks, dependencies, and time-based triggers or intervals within an Airflow DAG (Directed Acyclic Graph), which represents the workflow, and then using Airflow’s scheduling capabilities to automatically trigger the execution of tasks based on the defined schedule. Airflow provides a visual interface for designing, monitoring, and managing workflows, making it a powerful tool for automating and orchestrating data workflows in a scalable and efficient manner.
a) We start a standalone Airflow web server for the ETL pipeline project. This standalone mode allows for running Airflow without any external dependencies such as a database or a scheduler, making it useful for quickly setting up a local instance of Airflow for experimentation or development.
Note: the standalone mode is not recommended for production use, as it does not provide the full functionality and scalability of a production-ready Airflow installation with a separate database, scheduler, and other necessary components.
Run the following command to start a standalone Airflow web server.
airflow standalone

Creating standalone Airflow web server
Note: a login credential in provided in the command line to access the Airflow. copy this and keep this for the next part.
b) For the next step, we access the Airflow console via the EC2 public DNS.

Public IPV4 DNS
Then enter the login credentials stated above to log into the Airflow console.

Airflow Console Login page

Airflow Console Home page
c) To deploy the python scripts on the EC2, navigate to the ‘airflow’ folder in the home directory. Then, we create a directory called ‘etl_reddit_dag’, where we will deploy our python scripts for the project.
visit my github repository for the full code used in this project.

Next, we edit the ‘dags_folder’ variable in the airflow.cfg file and specify the above the absolute path of the ‘etl_reddit_dag’ as its value. To do this, we open the airflow.cfg file with Nano editor and make the changes.
dags_folder = /home/ubuntu/airflow/etl_reddit_dag
d) Click on the play button at the top right corner of the screen and click on “Trigger DAG”.

Triggering ‘ETL_DAG’ DAG

DAG executes successfully
e) Now, we navigate to the S3 bucket to confirm data was successfully stored.

Data stored in S3 bucket
Summary
This article outlines the steps to create a simple ETL (Extract, Transform, Load) pipeline using RedditAPI and Apache Airflow. It involves spinning up an EC2 instance on AWS, installing required packages, deploying python scripts, and scheduling the workflow using Airflow. The article also provides instructions on how to trigger the DAG (Directed Acyclic Graph) and confirm data storage in an S3 bucket.